Prima di immergerci nel caos, ricordiamoci perché ci siamo innamorati dell'event sourcing in primo luogo:
- Tracciabilità completa? Fatto.
- Capacità di ricostruire stati passati? Fatto.
- Flessibilità per evolvere il nostro modello di dominio? Fatto.
- Vantaggi di scalabilità e prestazioni? Doppiamente fatto.
Sembrava tutto troppo bello per essere vero. Spoiler: lo era.
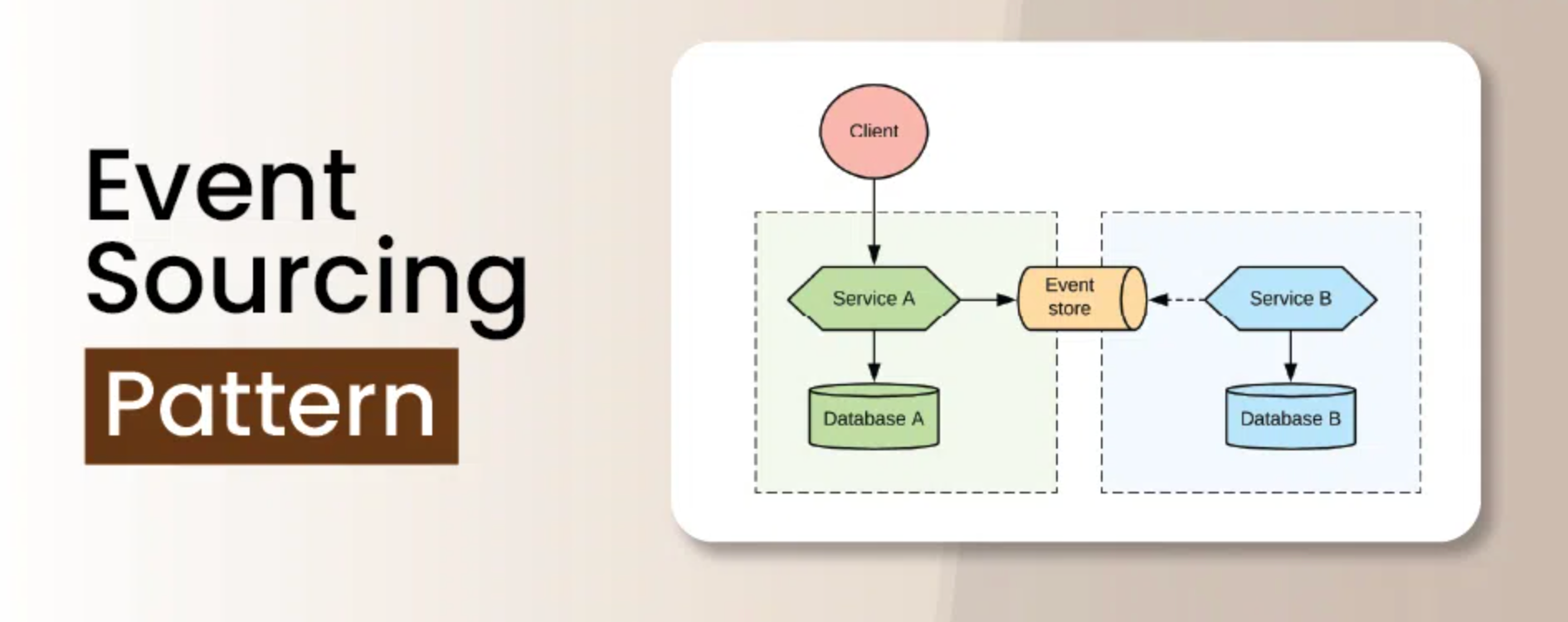
L'Impostazione: Il Nostro Sistema di Gestione dell'Inventario
Il nostro sistema è stato progettato per gestire milioni di SKU in diversi magazzini. Abbiamo scelto l'event sourcing per mantenere una cronologia precisa di ogni movimento di stock, cambio di prezzo e aggiornamento degli attributi degli articoli. L'event store era la nostra fonte di verità, con proiezioni che fornivano lo stato attuale per query rapide.
Ecco una versione semplificata della nostra struttura degli eventi:
{
"eventId": "e123456-7890-abcd-ef12-34567890abcd",
"eventType": "StockAdded",
"aggregateId": "SKU123456",
"timestamp": "2023-04-01T12:00:00Z",
"data": {
"quantity": 100,
"warehouseId": "WH001"
},
"version": 1
}Sembra abbastanza innocente, vero? Oh, quanto eravamo ingenui.
Il Disfacimento: Insidie del Versionamento degli Eventi
Il nostro primo grande intoppo è arrivato quando abbiamo dovuto aggiornare il nostro evento StockAdded per includere un campo reason. Sembrava semplice, pensavamo. Basta aumentare la versione e aggiungere una strategia di migrazione. Cosa potrebbe andare storto?
Tutto. Tutto potrebbe andare storto.
Lezione 1: Versiona i Tuoi Eventi Come Se La Tua Vita Dipendesse Da Questo
Abbiamo commesso l'errore classico di usare un unico numero di versione per tutti gli eventi. Questo significava che quando abbiamo aggiornato StockAdded, abbiamo involontariamente interrotto l'elaborazione di tutti gli altri eventi.
Ecco cosa avremmo dovuto fare:
{
"eventType": "StockAdded",
"eventVersion": 2,
"data": {
"quantity": 100,
"warehouseId": "WH001",
"reason": "Initial stock"
}
}Versionando ogni tipo di evento in modo indipendente, avremmo potuto evitare l'effetto domino che ha messo in ginocchio il nostro sistema.
Lezione 2: Le Migrazioni Non Sono Opzionali
Inizialmente pensavamo di poter gestire entrambe le versioni nei nostri gestori di eventi. Grande errore. Man mano che il sistema cresceva, questo approccio è diventato insostenibile.
Invece, avremmo dovuto implementare una strategia di migrazione robusta:
def migrate_stock_added_v1_to_v2(event):
if event['eventVersion'] == 1:
event['data']['reason'] = 'Legacy import'
event['eventVersion'] = 2
return event
# Applica le migrazioni quando si legge dall'event store
events = [migrate_stock_added_v1_to_v2(e) for e in read_events()]
La Saga degli Snapshot: Quando le Ottimizzazioni Si Rivoltano Contro
Man mano che il nostro event store cresceva, ricostruire le proiezioni diventava dolorosamente lento. Entrano in gioco gli snapshot: il nostro presunto salvatore che si è trasformato in un altro incubo.
Lezione 3: La Frequenza degli Snapshot È un Equilibrio Delicato
Inizialmente creavamo snapshot ogni 100 eventi. Questo funzionava bene fino a quando non abbiamo avuto un improvviso picco di transazioni, causando un ritardo nella creazione degli snapshot e le nostre proiezioni diventavano sempre più obsolete.
La soluzione? Frequenza degli snapshot adattiva:
def should_create_snapshot(aggregate):
time_since_last_snapshot = current_time() - aggregate.last_snapshot_time
events_since_last_snapshot = aggregate.event_count - aggregate.last_snapshot_event_count
return (time_since_last_snapshot > MAX_TIME_BETWEEN_SNAPSHOTS or
events_since_last_snapshot > MAX_EVENTS_BETWEEN_SNAPSHOTS)
Lezione 4: Anche gli Snapshot Hanno Bisogno di Versionamento
Abbiamo dimenticato di versionare i nostri snapshot. Quando abbiamo cambiato la struttura del nostro aggregato, tutto è andato a rotoli. Gli snapshot più vecchi sono diventati incompatibili e non siamo riusciti a ricostruire le nostre proiezioni.
La soluzione? Versiona i tuoi snapshot e fornisci percorsi di aggiornamento:
def upgrade_snapshot(snapshot):
if snapshot['version'] == 1:
snapshot['data']['newField'] = calculate_new_field(snapshot['data'])
snapshot['version'] = 2
return snapshot
# Usa quando carichi gli snapshot
snapshot = upgrade_snapshot(load_snapshot(aggregate_id))
Il Dilemma della Corruzione: Quando la Tua Fonte di Verità Mente
L'ultimo chiodo nella nostra bara è stata la corruzione dell'event store. Una tempesta perfetta di problemi di rete, un bug nel nostro event store e una gestione degli errori troppo aggressiva hanno portato a eventi duplicati e mancanti.
Lezione 5: Fidati, ma Verifica
Abbiamo ciecamente fidato nel nostro event store. Invece, avremmo dovuto implementare checksum e controlli di integrità periodici:
def verify_event_integrity(event):
expected_hash = calculate_hash(event['data'])
return event['hash'] == expected_hash
def perform_integrity_check():
for event in read_all_events():
if not verify_event_integrity(event):
raise IntegrityError(f"Corrupt event detected: {event['eventId']}")
Lezione 6: Implementa una Strategia di Recupero
Quando si verifica una corruzione (e succederà), hai bisogno di un modo per recuperare. Noi non ne avevamo uno, e ci è costato caro. Ecco cosa avremmo dovuto fare:
- Mantenere un log separato, solo in append, di tutti i comandi in arrivo.
- Implementare un processo di riconciliazione per confrontare il log dei comandi con l'event store.
- Creare un processo di recupero per riprodurre eventi mancanti o rimuovere duplicati.
def reconcile_events():
command_log = read_command_log()
event_store = read_event_store()
for command in command_log:
if not event_exists_for_command(command, event_store):
replay_command(command)
for event in event_store:
if is_duplicate_event(event, event_store):
remove_duplicate_event(event)
La Fenice Risorge: Ricostruire con Resilienza
Dopo innumerevoli notti insonni e più caffè di quanto mi piacerebbe ammettere, abbiamo finalmente stabilizzato il nostro sistema. Ecco i punti chiave che ci hanno aiutato a risorgere dalle ceneri:
- Il versionamento degli eventi non è opzionale – fallo dal primo giorno.
- Implementa strategie di migrazione robuste sia per gli eventi che per gli snapshot.
- La creazione adattiva degli snapshot bilancia prestazioni e coerenza.
- Non fidarti di nulla – implementa controlli di integrità a ogni livello.
- Avere una chiara strategia di recupero prima di averne bisogno.
- Test estensivi, inclusa l'ingegneria del caos, possono salvarti la pelle.
Conclusione: La Spada a Doppio Taglio dell'Event Sourcing
L'event sourcing è potente, ma è anche complesso. Non è una soluzione magica e richiede una considerazione attenta e pratiche ingegneristiche robuste per avere successo in produzione.
Ricorda, con grande potere viene grande responsabilità – e nel caso dell'event sourcing, molte notti insonni. Ma armato di queste lezioni, sei ora meglio preparato per affrontare le sfide dell'event sourcing nel mondo reale.
Ora, se mi scusate, ho un po' di PTSD da affrontare. Qualcuno conosce un buon terapeuta specializzato in traumi da event sourcing?
"Nell'event sourcing, come nella vita, non si tratta di evitare i fallimenti – si tratta di fallire con grazia e recuperare più forti."
Ulteriori Letture
- EventStore - Un database di flusso costruito per l'event sourcing
- Progetto m-r di Greg Young - Una semplice implementazione di CQRS e event sourcing
- Martin Fowler sull'Event Sourcing
Hai combattuto i tuoi demoni dell'event sourcing? Condividi le tue storie di guerra nei commenti – la miseria ama la compagnia, dopotutto!