I filtri di Bloom sono come i buttafuori del mondo dei dati: ti dicono rapidamente se qualcosa è probabilmente nel club (il tuo dataset) o sicuramente no, senza dover aprire le porte. Questa struttura dati probabilistica può ridurre significativamente le ricerche inutili e le chiamate di rete, rendendo il tuo sistema più veloce ed efficiente.
La Magia Dietro le Quinte
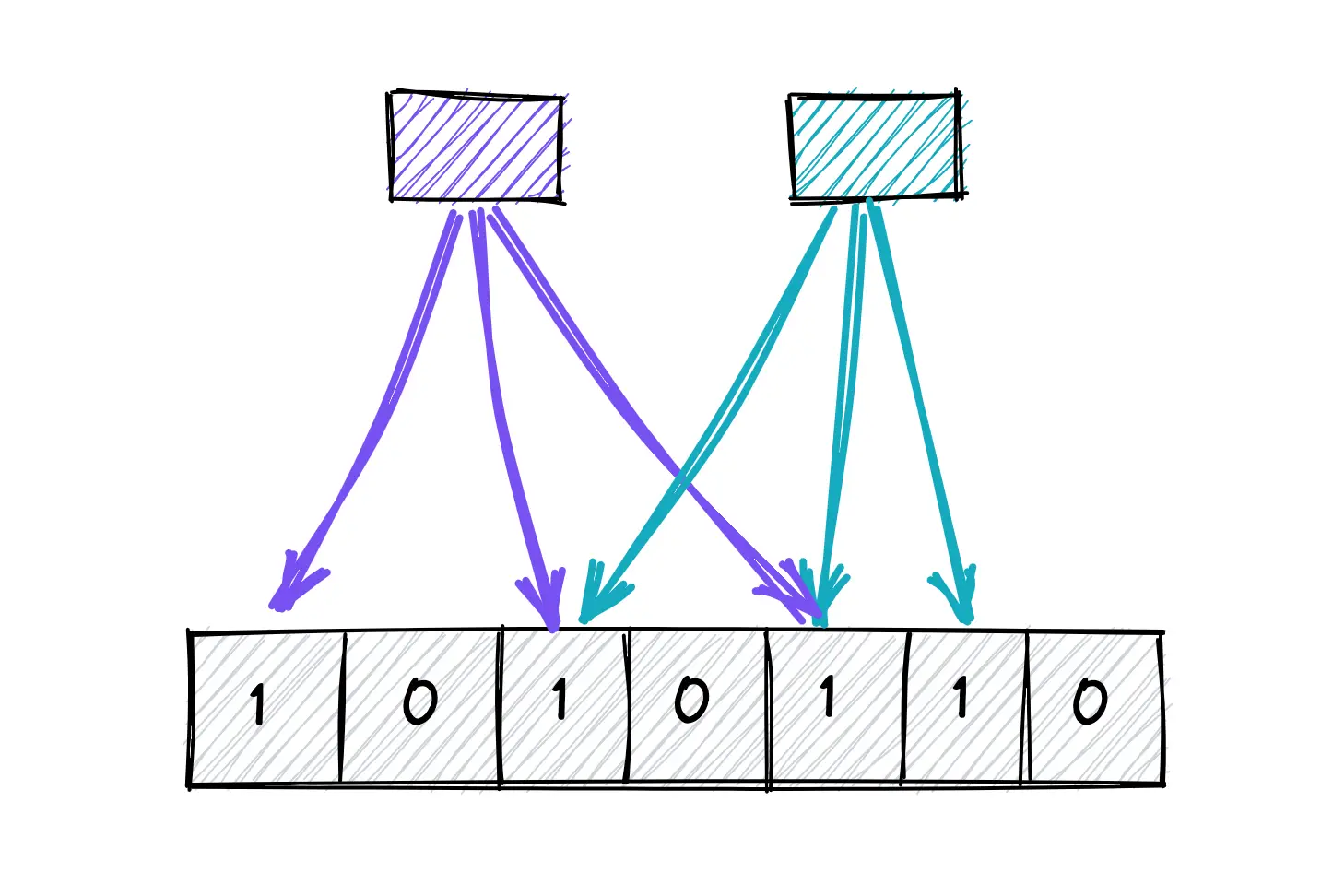
Alla base, un filtro di Bloom è un array di bit. Quando aggiungi un elemento, viene hashato più volte e i bit corrispondenti vengono impostati su 1. Controllare se un elemento esiste comporta l'hashing di nuovo e la verifica se tutti i bit corrispondenti sono impostati. È semplice, ma potente.
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = [0] * size
def add(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
self.bit_array[index] = 1
def check(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
if self.bit_array[index] == 0:
return False
return True
Applicazioni Reali: Dove i Filtri di Bloom Brillano
Esploriamo alcuni scenari pratici in cui i filtri di Bloom possono fare la differenza:
1. Sistemi di Caching: Il Guardiano
Immagina di gestire un sistema di caching su larga scala. Prima di accedere allo storage di backend costoso, puoi usare un filtro di Bloom per verificare se la chiave potrebbe esistere nella cache.
def get_item(key):
if not bloom_filter.check(key):
return None # Sicuramente non nella cache
# Potrebbe essere nella cache, controlliamo
return actual_cache.get(key)
Questo semplice controllo può ridurre drasticamente i cache miss e le query di backend non necessarie.
2. Ottimizzazione della Ricerca: Il Rapido Eliminatore
In un sistema di ricerca distribuito, i filtri di Bloom possono agire come pre-filtri per eliminare ricerche non necessarie tra le shard.
def search_shards(query):
results = []
for shard in shards:
if shard.bloom_filter.check(query):
results.extend(shard.search(query))
return results
Eliminando rapidamente le shard che sicuramente non contengono la query, puoi ridurre il traffico di rete e migliorare i tempi di ricerca.
3. Rilevamento dei Duplicati: L'Efficiente Deduplicatore
Quando si esegue il crawling del web o si elaborano grandi flussi di dati, rilevare rapidamente i duplicati è cruciale.
def process_item(item):
if not bloom_filter.check(item):
bloom_filter.add(item)
process_new_item(item)
else:
# Possibilmente già visto, fare ulteriori controlli
pass
Questo approccio può ridurre significativamente l'uso della memoria rispetto a mantenere un elenco completo degli elementi elaborati.
Dettagli: Ottimizzare il Tuo Filtro di Bloom
Come ogni buon strumento, i filtri di Bloom necessitano di una corretta ottimizzazione. Ecco alcune considerazioni chiave:
- La dimensione conta: Più grande è il filtro, minore è il tasso di falsi positivi, ma maggiore è l'uso della memoria.
- Funzioni hash: Più funzioni hash riducono i falsi positivi ma aumentano il tempo di calcolo.
- Numero previsto di elementi: Conoscere la dimensione dei tuoi dati aiuta a ottimizzare i parametri del filtro.
Ecco una formula rapida per aiutarti a dimensionare il tuo filtro di Bloom:
import math
def optimal_bloom_filter_size(item_count, false_positive_rate):
m = -(item_count * math.log(false_positive_rate)) / (math.log(2)**2)
k = (m / item_count) * math.log(2)
return int(m), int(k)
# Esempio di utilizzo
items = 1000000
fp_rate = 0.01
size, hash_count = optimal_bloom_filter_size(items, fp_rate)
print(f"Dimensione ottimale: {size} bit")
print(f"Numero ottimale di hash: {hash_count}")
Trappole e Considerazioni
Prima di impazzire con i filtri di Bloom, tieni a mente questi punti:
- I falsi positivi esistono: I filtri di Bloom possono indicare che un elemento potrebbe essere presente quando non lo è. Pianifica questo nel tuo handling degli errori.
- Nessuna cancellazione: I filtri di Bloom standard non supportano la rimozione degli elementi. Esamina i Counting Bloom Filters se hai bisogno di questa funzionalità.
- Non è una soluzione universale: Sebbene potenti, i filtri di Bloom non sono adatti a ogni scenario. Valuta attentamente il tuo caso d'uso.
"Con grande potere viene grande responsabilità. Usa i filtri di Bloom con saggezza, e tratteranno bene il tuo backend." - Zio Ben (se fosse un architetto software)
Integrare i Filtri di Bloom nel Tuo Stack
Pronto a provare i filtri di Bloom? Ecco alcune librerie popolari per iniziare:
- Guava per sviluppatori Java
- pybloom per appassionati di Python
- bloomd per un servizio di rete standalone
Il Quadro Generale: Perché Preoccuparsi?
Nell'insieme, i filtri di Bloom sono più di un semplice trucco intelligente. Rappresentano un principio più ampio nel design dei sistemi: a volte, un po' di incertezza può portare a enormi guadagni in termini di prestazioni. Accettando una piccola probabilità di falsi positivi, possiamo creare sistemi più veloci, scalabili ed efficienti.
Spunti di Riflessione
Mentre implementi i filtri di Bloom nella tua architettura, considera queste domande:
- Come può la natura probabilistica dei filtri di Bloom influenzare altre parti del design del tuo sistema?
- In quali altri scenari potrebbe essere vantaggioso scambiare la precisione perfetta per la velocità?
- Come si allinea l'uso dei filtri di Bloom con gli SLA e i budget di errore del tuo sistema?
Conclusione: Il Bloom è Fuori dalla Rosa
I filtri di Bloom potrebbero non essere la novità del momento, ma sono uno strumento collaudato e robusto che merita un posto nel tuo toolkit di backend. Dal caching all'ottimizzazione della ricerca, questi potenti strumenti probabilistici possono dare ai tuoi sistemi distribuiti il boost di prestazioni di cui hanno bisogno.
Quindi, la prossima volta che ti trovi di fronte a un diluvio di dati o a un pantano di query, ricorda: a volte, la soluzione è in fiore.
Ora vai avanti e filtra, magnifici maestri del backend!