La gestione efficace degli errori nei sistemi basati su eventi, specialmente quando si utilizza Kafka, richiede la propagazione di errori contestualizzati tra i topic. Esploreremo strategie per mantenere il contesto degli errori, progettare eventi di errore e implementare modelli di gestione degli errori robusti. Alla fine, sarai in grado di domare il caos degli errori distribuiti e mantenere il tuo sistema funzionante senza intoppi.
Il Dilemma della Gestione degli Errori
Le architetture basate su eventi sono ottime per costruire sistemi scalabili e disaccoppiati. Ma quando si tratta di gestione degli errori, le cose possono diventare... interessanti. A differenza delle applicazioni monolitiche dove puoi facilmente tracciare l'origine di un errore, i sistemi distribuiti presentano una sfida unica: gli errori possono verificarsi ovunque, in qualsiasi momento, e i loro effetti possono propagarsi in tutto il sistema.
Quindi, cosa rende la gestione degli errori nei sistemi basati su eventi, in particolare quelli che utilizzano Kafka, così complicata?
- Natura asincrona degli eventi
- Servizi disaccoppiati
- Potenziale di fallimenti a cascata
- Perdita del contesto degli errori tra i confini dei servizi
Affrontiamo queste sfide e vediamo come possiamo propagare errori contestualizzati tra i topic di Kafka come dei professionisti.
Progettare Eventi di Errore Contestualizzati
Il primo passo per una gestione efficace degli errori è progettare eventi di errore che contengano abbastanza contesto per essere utili. Ecco come potrebbe apparire un evento di errore ben progettato:
{
"errorId": "e12345-67890-abcdef",
"timestamp": "2023-04-15T14:30:00Z",
"sourceService": "payment-processor",
"errorType": "PAYMENT_FAILURE",
"errorMessage": "Carta di credito rifiutata",
"correlationId": "order-123456",
"stackTrace": "...",
"metadata": {
"orderId": "order-123456",
"userId": "user-789012",
"amount": 99.99
}
}
Questo evento di errore include:
- Un ID errore unico per il tracciamento
- Timestamp per quando si è verificato l'errore
- Servizio di origine per identificare dove è nato l'errore
- Tipo di errore e messaggio per una rapida comprensione
- ID di correlazione per collegare eventi correlati
- Stack trace per il debug dettagliato
- Metadati rilevanti per fornire contesto
Implementare la Propagazione degli Errori
Ora che abbiamo la struttura del nostro evento di errore, vediamo come implementare la propagazione degli errori tra i topic di Kafka.
1. Creare un Topic di Errore Dedicato
Per prima cosa, crea un topic di Kafka dedicato agli errori. Questo ti permette di centralizzare la gestione degli errori e rende più facile monitorare e processare gli errori separatamente dagli eventi regolari.
kafka-topics.sh --create --topic error-events --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092
2. Implementare i Produttori di Errori
Nei tuoi servizi, implementa produttori di errori che inviano eventi di errore al topic di errore dedicato quando si verificano eccezioni. Ecco un semplice esempio usando Java e il client Kafka:
public class ErrorProducer {
private final KafkaProducer producer;
private static final String ERROR_TOPIC = "error-events";
public ErrorProducer(Properties kafkaProps) {
this.producer = new KafkaProducer<>(kafkaProps);
}
public void sendErrorEvent(ErrorEvent errorEvent) {
String errorJson = convertToJson(errorEvent);
ProducerRecord record = new ProducerRecord<>(ERROR_TOPIC, errorEvent.getErrorId(), errorJson);
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// Gestisci il caso in cui l'invio dell'evento di errore stesso fallisce
System.err.println("Invio dell'evento di errore fallito: " + exception.getMessage());
}
});
}
private String convertToJson(ErrorEvent errorEvent) {
// Implementa qui la logica di conversione in JSON
}
}
3. Implementare i Consumatori di Errori
Crea consumatori di errori che processano gli eventi di errore dal topic di errore. Questi consumatori possono eseguire varie azioni come logging, allerta o attivazione di azioni compensative.
public class ErrorConsumer {
private final KafkaConsumer consumer;
private static final String ERROR_TOPIC = "error-events";
public ErrorConsumer(Properties kafkaProps) {
this.consumer = new KafkaConsumer<>(kafkaProps);
consumer.subscribe(Collections.singletonList(ERROR_TOPIC));
}
public void consumeErrors() {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
ErrorEvent errorEvent = parseErrorEvent(record.value());
processError(errorEvent);
}
}
}
private ErrorEvent parseErrorEvent(String json) {
// Implementa qui la logica di parsing JSON
}
private void processError(ErrorEvent errorEvent) {
// Implementa qui la logica di gestione degli errori (logging, allerta, ecc.)
}
}
Modelli Avanzati di Gestione degli Errori
Ora che abbiamo le basi, esploriamo alcuni modelli avanzati per la gestione degli errori nei sistemi basati su eventi.
1. Modello Circuit Breaker
Implementa circuit breaker per prevenire fallimenti a cascata quando un servizio sta sperimentando errori ripetuti. Questo modello può aiutare il tuo sistema a degradare e recuperare in modo elegante.
public class CircuitBreaker {
private final long timeout;
private final int failureThreshold;
private int failureCount;
private long lastFailureTime;
private State state;
public CircuitBreaker(long timeout, int failureThreshold) {
this.timeout = timeout;
this.failureThreshold = failureThreshold;
this.state = State.CLOSED;
}
public boolean allowRequest() {
if (state == State.OPEN) {
if (System.currentTimeMillis() - lastFailureTime > timeout) {
state = State.HALF_OPEN;
return true;
}
return false;
}
return true;
}
public void recordSuccess() {
failureCount = 0;
state = State.CLOSED;
}
public void recordFailure() {
failureCount++;
lastFailureTime = System.currentTimeMillis();
if (failureCount >= failureThreshold) {
state = State.OPEN;
}
}
private enum State {
CLOSED, OPEN, HALF_OPEN
}
}
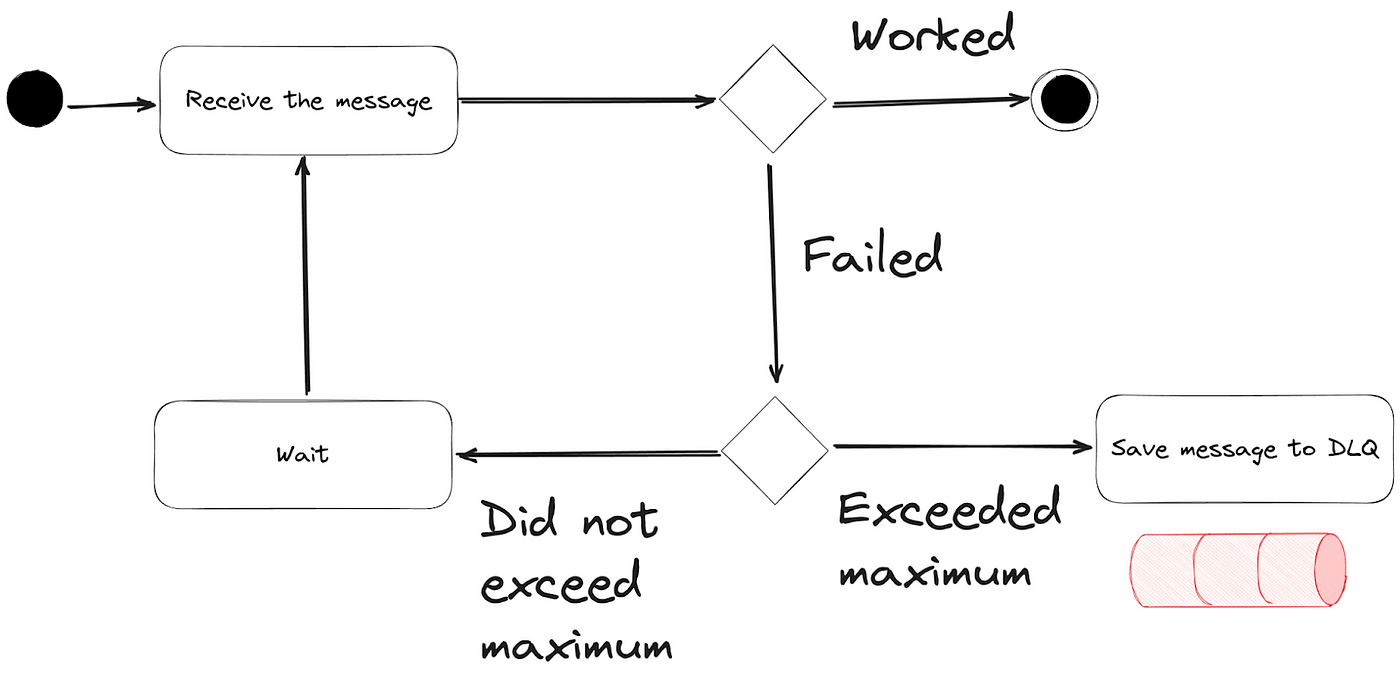
2. Coda di Messaggi Morti
Implementa una coda di messaggi morti (DLQ) per i messaggi che falliscono ripetutamente nel processamento. Questo ti permette di isolare eventi problematici per un'analisi e un rielaborazione successiva.
public class DeadLetterQueue {
private final KafkaProducer producer;
private static final String DLQ_TOPIC = "dead-letter-queue";
public DeadLetterQueue(Properties kafkaProps) {
this.producer = new KafkaProducer<>(kafkaProps);
}
public void sendToDLQ(String key, String value, String reason) {
DLQEvent dlqEvent = new DLQEvent(key, value, reason);
String dlqJson = convertToJson(dlqEvent);
ProducerRecord record = new ProducerRecord<>(DLQ_TOPIC, key, dlqJson);
producer.send(record);
}
private String convertToJson(DLQEvent dlqEvent) {
// Implementa qui la logica di conversione in JSON
}
}
3. Riprova con Backoff
Implementa un meccanismo di riprova con backoff esponenziale per errori transitori. Questo può aiutare il tuo sistema a recuperare da fallimenti temporanei senza sovraccaricare il componente in errore.
public class RetryWithBackoff {
private final int maxRetries;
private final long initialBackoff;
public RetryWithBackoff(int maxRetries, long initialBackoff) {
this.maxRetries = maxRetries;
this.initialBackoff = initialBackoff;
}
public void executeWithRetry(Runnable task) throws Exception {
int attempts = 0;
while (attempts < maxRetries) {
try {
task.run();
return;
} catch (Exception e) {
attempts++;
if (attempts >= maxRetries) {
throw e;
}
long backoff = initialBackoff * (long) Math.pow(2, attempts - 1);
Thread.sleep(backoff);
}
}
}
}
Monitoraggio e Osservabilità
Implementare una gestione robusta degli errori è ottimo, ma devi anche tenere d'occhio la salute del tuo sistema. Ecco alcuni consigli per il monitoraggio e l'osservabilità:
- Usa strumenti di tracciamento distribuito come Jaeger o Zipkin per tracciare le richieste tra i servizi
- Implementa endpoint di controllo della salute nei tuoi servizi
- Imposta allerta basate su tassi di errore e modelli
- Usa strumenti di aggregazione dei log per centralizzare e analizzare i log
- Crea dashboard per visualizzare le tendenze degli errori e la salute del sistema
Conclusione: Domare il Caos
La gestione degli errori nei sistemi basati su eventi, specialmente quando si lavora con Kafka, può essere una sfida. Ma con l'approccio giusto, puoi trasformare il potenziale caos in una macchina ben oliata. Progettando eventi di errore contestualizzati, implementando una corretta propagazione degli errori e utilizzando modelli avanzati di gestione degli errori, sarai sulla buona strada per costruire sistemi basati su eventi resilienti e manutenibili.
Ricorda, una gestione efficace degli errori non riguarda solo la cattura delle eccezioni, ma anche fornire un contesto significativo, facilitare un debug rapido e garantire che il tuo sistema possa recuperare elegantemente dai fallimenti. Quindi vai avanti, implementa questi modelli e che i tuoi topic di Kafka siano sempre consapevoli degli errori!
"L'arte della programmazione è l'arte di organizzare la complessità, di padroneggiare la moltitudine e di evitare il suo caos bastardo nel modo più efficace possibile." - Edsger W. Dijkstra
Ora, armato di queste tecniche, sei pronto ad affrontare anche gli scenari di errore più complessi nei tuoi sistemi basati su eventi. Buona programmazione, e che i tuoi errori siano sempre contestualizzati!