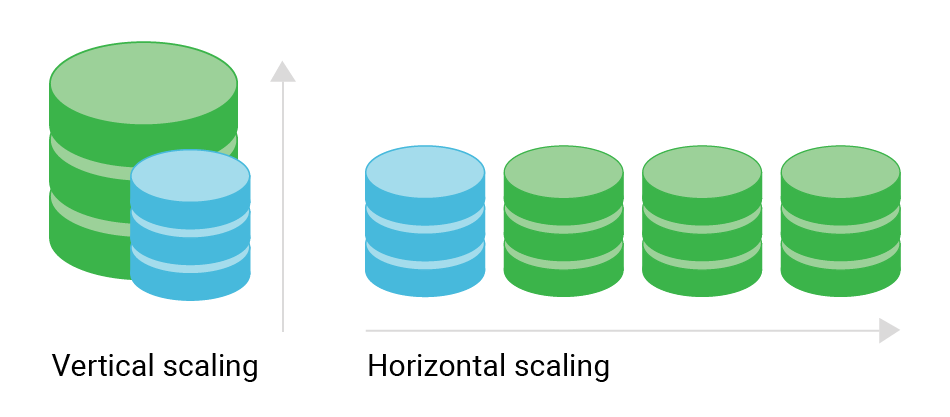
Scalare non significa solo aggiungere più hardware al problema (anche se questo può aiutare). Si tratta di distribuire intelligentemente i dati per gestire un carico maggiore, garantire alta disponibilità e mantenere le prestazioni. Ecco che entrano in gioco i nostri due protagonisti: sharding e replica.
Sharding: Tagliare la Torta dei Dati
Immagina il tuo database come una pizza enorme. Lo sharding è come tagliare quella pizza in fette e distribuirle su diversi piatti (server). Ogni fetta (shard) contiene una parte dei tuoi dati, permettendoti di distribuire il carico e migliorare le prestazioni delle query.
Come Funziona lo Sharding?
Alla base, lo sharding implica la partizione dei dati in base a qualche criterio. Questo potrebbe essere:
- Basato su intervalli: Dividere i dati per intervalli di valori (es. utenti A-M su uno shard, N-Z su un altro)
- Basato su hash: Usare una funzione hash per determinare a quale shard appartengono i dati
- Basato sulla geografia: Memorizzare i dati sugli shard più vicini agli utenti che li accedono
Ecco un semplice esempio di come potresti implementare lo sharding basato su intervalli in uno scenario ipotetico:
def get_shard(user_id):
if user_id < 1000000:
return "shard_1"
elif user_id < 2000000:
return "shard_2"
else:
return "shard_3"
# Uso
user_data = get_user_data(user_id)
shard = get_shard(user_id)
save_to_database(shard, user_data)
Il Buono, il Brutto e lo Sharded
Lo sharding non è tutto rose e fiori. Vediamo i dettagli:
Vantaggi:
- Miglioramento delle prestazioni delle query
- Scalabilità orizzontale
- Riduzione della dimensione dell'indice per shard
Svantaggi:
- Aumento della complessità nella logica dell'applicazione
- Potenziale squilibrio nella distribuzione dei dati
- Sfide con le operazioni cross-shard
"Lo sharding è come giocolare con le motoseghe. È impressionante quando fatto bene, ma un errore e le cose si complicano." - DBA Anonimo
Replica: L'Arte del Clonare i Dati
Se lo sharding riguarda il dividere e conquistare, la replica riguarda il vecchio adagio: "due teste sono meglio di una." La replica implica la creazione di copie dei tuoi dati su più nodi, fornendo ridondanza e migliorando le prestazioni di lettura.
Architetture di Replica
Esistono due principali architetture di replica:
1. Replica Master-Slave
In questa configurazione, un nodo (il master) gestisce le scritture, mentre più nodi slave gestiscono le letture. È come avere un cuoco (master) che prepara i pasti, con più camerieri (slave) che li servono ai clienti.
2. Replica Master-Master
Qui, più nodi possono gestire sia le letture che le scritture. È come avere più cuochi, ognuno in grado di preparare e servire i pasti.
Ecco una rappresentazione semplificata in pseudo-codice di come potresti implementare la replica master-slave:
class Database:
def __init__(self, is_master=False):
self.is_master = is_master
self.data = {}
self.slaves = []
def write(self, key, value):
if self.is_master:
self.data[key] = value
for slave in self.slaves:
slave.replicate(key, value)
else:
raise Exception("Cannot write to slave")
def read(self, key):
return self.data.get(key)
def replicate(self, key, value):
self.data[key] = value
# Uso
master = Database(is_master=True)
slave1 = Database()
slave2 = Database()
master.slaves = [slave1, slave2]
master.write("user_1", {"name": "Alice", "age": 30})
print(slave1.read("user_1")) # Output: {"name": "Alice", "age": 30}
Replica: Vantaggi e Svantaggi
Vantaggi:
- Miglioramento delle prestazioni di lettura
- Alta disponibilità e tolleranza ai guasti
- Distribuzione geografica dei dati
Svantaggi:
- Potenziale di inconsistenza dei dati
- Aumento dei requisiti di archiviazione
- Complessità nella gestione di più nodi
Sharding vs. Replica: La Sfida Finale?
Non proprio. In effetti, lo sharding e la replica spesso funzionano meglio quando usati insieme. Pensalo come un match di coppia dove lo sharding gestisce il grosso del lavoro di distribuzione dei dati, mentre la replica assicura che il tuo sistema rimanga attivo anche quando i singoli nodi si guastano.
Ecco una rapida matrice decisionale per aiutarti a scegliere:
| Caso d'Uso | Sharding | Replica |
|---|---|---|
| Migliorare le prestazioni di scrittura | ✅ | ❌ |
| Migliorare le prestazioni di lettura | ✅ | ✅ |
| Alta disponibilità | ❌ | ✅ |
| Ridondanza dei dati | ❌ | ✅ |
Il Teorema CAP: Devi Scegliere Due
Quando si scalano i database, inevitabilmente ci si imbatte nel teorema CAP. Esso afferma che in un sistema distribuito, puoi avere solo due delle tre seguenti caratteristiche: Consistenza, Disponibilità e Tolleranza alle Partizioni. Questo porta a interessanti compromessi:
- Sistemi CA: Prioritizzano consistenza e disponibilità ma non possono gestire le partizioni di rete
- Sistemi CP: Mantengono consistenza e tolleranza alle partizioni ma possono sacrificare la disponibilità
- Sistemi AP: Si concentrano su disponibilità e tolleranza alle partizioni, potenzialmente a scapito della consistenza
La maggior parte dei moderni database distribuiti rientra nelle categorie CP o AP, con varie strategie per mitigare gli svantaggi della loro scelta.
Implementare Sharding e Replica nei Database Popolari
Facciamo un rapido tour di come alcuni database popolari gestiscono sharding e replica:
MongoDB
MongoDB supporta sia lo sharding che la replica nativamente. Utilizza una chiave shard per distribuire i dati su più shard e fornisce set di replica per alta disponibilità.
// Abilita lo sharding per un database
sh.enableSharding("mydb")
// Shard di una collezione
sh.shardCollection("mydb.users", { "user_id": "hashed" })
// Crea un set di replica
rs.initiate({
_id: "myReplicaSet",
members: [
{ _id: 0, host: "mongodb0.example.net:27017" },
{ _id: 1, host: "mongodb1.example.net:27017" },
{ _id: 2, host: "mongodb2.example.net:27017" }
]
})
PostgreSQL
PostgreSQL non ha lo sharding integrato ma lo supporta tramite estensioni come Citus. Tuttavia, ha robuste funzionalità di replica.
-- Configura la replica in streaming
ALTER SYSTEM SET wal_level = replica;
ALTER SYSTEM SET max_wal_senders = 10;
ALTER SYSTEM SET max_replication_slots = 10;
-- Sul server standby
CREATE SUBSCRIPTION my_subscription
CONNECTION 'host=primary_host port=5432 dbname=mydb'
PUBLICATION my_publication;
MySQL
MySQL offre sia capacità di sharding (tramite MySQL Cluster) che di replica.
-- Configura la replica master-slave
-- Sul master
CREATE USER 'repl'@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
-- Sullo slave
CHANGE MASTER TO
MASTER_HOST='master_host_name',
MASTER_USER='repl',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=73;
START SLAVE;
Best Practice per Scalare il Tuo Database
Mentre concludiamo il nostro viaggio nel mondo della scalabilità dei database, ecco alcune regole d'oro da tenere a mente:
- Pianifica in anticipo: Progetta il tuo schema e la tua applicazione con la scalabilità in mente fin dall'inizio.
- Monitora e analizza: Controlla regolarmente le prestazioni del tuo database e identifica i colli di bottiglia.
- Inizia semplice: Inizia con la scalabilità verticale e ottimizza le query prima di passare allo sharding.
- Scegli saggiamente la tua chiave shard: Una cattiva chiave shard può portare a una distribuzione disomogenea dei dati e a punti caldi.
- Testa, testa, testa: Testa sempre a fondo la tua strategia di scalabilità in un ambiente di staging prima della produzione.
- Considera i servizi gestiti: I fornitori di cloud offrono servizi di database gestiti che possono gestire gran parte della complessità della scalabilità per te.
Conclusione: Scalare a Nuove Altezze
Scalare i database è tanto un'arte quanto una scienza. Mentre lo sharding e la replica sono strumenti potenti nel tuo arsenale di scalabilità, non sono soluzioni magiche. Ogni approccio ha le sue sfide e compromessi.
Ricorda, l'obiettivo non è solo gestire più dati o utenti; è farlo mantenendo prestazioni, affidabilità e integrità dei dati. Mentre intraprendi il tuo viaggio di scalabilità, continua a imparare, rimani curioso e non aver paura di sperimentare.
Ora vai avanti e scala quei database! I tuoi utenti (e il tuo futuro io) ti ringrazieranno.
"L'unica cosa che scala con la complessità è la semplicità." - Sconosciuto
Hai storie di guerra o consigli sulla scalabilità dei database? Condividili nei commenti qui sotto. Impariamo dai successi e dai momenti di facepalm degli altri!