In breve
Implementare consumatori idempotenti in Kafka è fondamentale per garantire la coerenza dei dati e prevenire l'elaborazione duplicata. Esploreremo le migliori pratiche, le insidie comuni e alcuni trucchi ingegnosi per rendere i tuoi consumatori Kafka idempotenti come una funzione matematica.
Perché l'idempotenza è importante
Prima di addentrarci nei dettagli, facciamo un rapido riepilogo del perché ci stiamo occupando di idempotenza:
- Previene l'elaborazione duplicata dei messaggi
- Garantisce la coerenza dei dati nel tuo sistema
- Ti salva da sessioni di debug notturne e frustrazioni
- Rende il tuo sistema più resiliente ai fallimenti e ai tentativi di ripetizione
Ora che siamo tutti sulla stessa lunghezza d'onda, tuffiamoci nel vivo!
Migliori pratiche per implementare consumatori idempotenti
1. Usa identificatori unici per i messaggi
La prima regola del Club dei Consumatori Idempotenti è: Usa sempre identificatori unici per i messaggi. (La seconda regola è... beh, hai capito.)
Implementarlo è semplice:
public class KafkaMessage {
private String id;
private String payload;
// ... altri campi e metodi
}
public class IdempotentConsumer {
private Set processedMessageIds = new HashSet<>();
public void consume(KafkaMessage message) {
if (processedMessageIds.add(message.getId())) {
// Elabora il messaggio
processMessage(message);
} else {
// Messaggio già elaborato, saltalo
log.info("Saltando messaggio duplicato: {}", message.getId());
}
}
}
Consiglio: Usa UUID o una combinazione di topic, partizione e offset per i tuoi ID messaggio. È come dare a ogni messaggio il suo unico fiocco di neve!
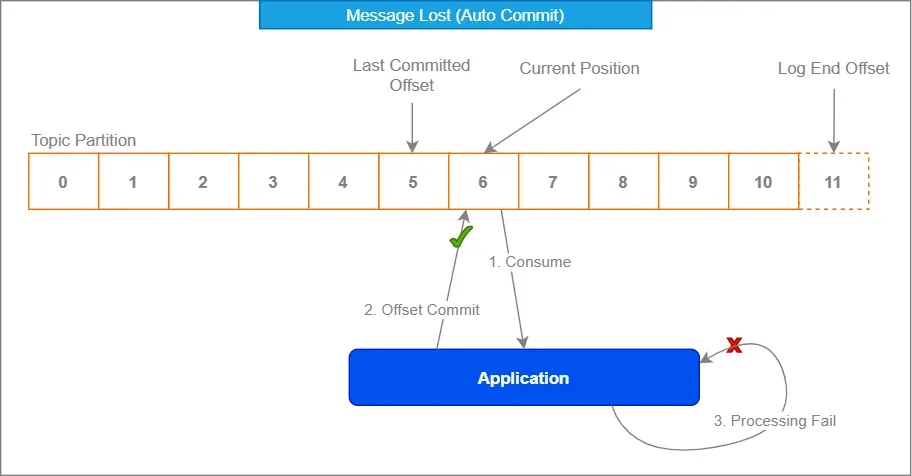
2. Sfrutta la gestione degli offset di Kafka
La gestione degli offset integrata di Kafka è tua amica. Abbracciala come quel parente strano alle riunioni di famiglia – potrebbe sembrare imbarazzante all'inizio, ma ti copre le spalle.
Properties props = new Properties();
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed");
KafkaConsumer consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
processRecord(record);
}
consumer.commitSync();
}
Disabilitando l'auto-commit e impegnando manualmente gli offset dopo l'elaborazione, ti assicuri che i messaggi siano contrassegnati come consumati solo quando sei sicuro al 100% che siano stati gestiti correttamente.
3. Implementa una strategia di deduplicazione
A volte, nonostante i nostri migliori sforzi, i duplicati si insinuano come ninja furtivi. È qui che una solida strategia di deduplicazione torna utile.
Considera l'uso di una cache distribuita come Redis per memorizzare gli ID dei messaggi elaborati:
@Service
public class DuplicateChecker {
private final RedisTemplate redisTemplate;
public DuplicateChecker(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean isDuplicate(String messageId) {
return !redisTemplate.opsForValue().setIfAbsent(messageId, "processed", Duration.ofDays(1));
}
}
Questo approccio ti consente di controllare i duplicati tra più istanze di consumatori e persino dopo i riavvii. È come avere un buttafuori per i tuoi messaggi – "Se il tuo ID non è nella lista, non entri!"
4. Usa operazioni idempotenti
Ogni volta che è possibile, progetta le tue operazioni di elaborazione dei messaggi per essere naturalmente idempotenti. Ciò significa che anche se un messaggio viene elaborato più volte, non influenzerà il risultato finale.
Ad esempio, invece di:
public void incrementCounter(String counterId) {
int currentValue = counterRepository.get(counterId);
counterRepository.set(counterId, currentValue + 1);
}
Considera l'uso di un'operazione atomica:
public void incrementCounter(String counterId) {
counterRepository.increment(counterId);
}
In questo modo, anche se l'operazione di incremento viene chiamata più volte per lo stesso messaggio, il risultato finale sarà lo stesso.
Trappole comuni e come evitarle
Ora che abbiamo coperto le basi, diamo un'occhiata ad alcune trappole comuni in cui anche gli sviluppatori esperti possono cadere:
1. Affidarsi esclusivamente alle semantiche "esattamente una volta" di Kafka
Sebbene Kafka offra semantiche "esattamente una volta", non è una soluzione miracolosa. Garantisce solo la consegna esattamente una volta all'interno del cluster Kafka, non l'elaborazione esattamente una volta end-to-end nella tua applicazione.
"Fidati, ma verifica" – Ronald Reagan (probabilmente parlando di messaggi Kafka)
Implementa sempre i tuoi controlli di idempotenza oltre alle garanzie di Kafka.
2. Ignorare i confini transazionali
Assicurati che l'elaborazione dei messaggi e i commit degli offset facciano parte della stessa transazione. Altrimenti, potresti trovarti in una situazione in cui hai elaborato un messaggio ma non hai impegnato l'offset, portando a una rielaborazione al riavvio del consumatore.
@Transactional
public void processMessage(ConsumerRecord record) {
// Elabora il messaggio
businessLogic.process(record.value());
// Riconosci manualmente il messaggio
acknowledgment.acknowledge();
}
3. Trascurare i vincoli del database
Se stai memorizzando dati elaborati in un database, usa i vincoli unici a tuo vantaggio. Possono fungere da ulteriore livello di protezione contro i duplicati.
CREATE TABLE processed_messages (
message_id VARCHAR(255) PRIMARY KEY,
processed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Quindi, nel tuo codice Java:
try {
jdbcTemplate.update("INSERT INTO processed_messages (message_id) VALUES (?)", messageId);
// Elabora il messaggio
} catch (DuplicateKeyException e) {
// Messaggio già elaborato, saltalo
}
Tecniche avanzate per i coraggiosi
Pronto a portare il tuo gioco di consumatori idempotenti al livello successivo? Ecco alcune tecniche avanzate per i più audaci:
1. Chiavi di idempotenza negli header
Invece di fare affidamento sul contenuto del messaggio per l'idempotenza, considera l'uso degli header dei messaggi Kafka per memorizzare le chiavi di idempotenza. Questo consente un contenuto del messaggio più flessibile mantenendo l'idempotenza.
// Produttore
ProducerRecord record = new ProducerRecord<>("my-topic", "key", "value");
record.headers().add("idempotency-key", UUID.randomUUID().toString().getBytes());
producer.send(record);
// Consumatore
ConsumerRecord record = // ... ricevuto da Kafka
byte[] idempotencyKeyBytes = record.headers().lastHeader("idempotency-key").value();
String idempotencyKey = new String(idempotencyKeyBytes, StandardCharsets.UTF_8);
2. Deduplicazione basata sul tempo
In alcuni scenari, potresti voler implementare una deduplicazione basata sul tempo. Questo è utile quando si gestiscono flussi di eventi in cui lo stesso evento potrebbe essere legittimamente ripetuto dopo un certo periodo.
public class TimeBasedDuplicateChecker {
private final RedisTemplate redisTemplate;
private final Duration deduplicationWindow;
public TimeBasedDuplicateChecker(RedisTemplate redisTemplate, Duration deduplicationWindow) {
this.redisTemplate = redisTemplate;
this.deduplicationWindow = deduplicationWindow;
}
public boolean isDuplicate(String messageId) {
String key = "dedup:" + messageId;
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(key, "processed", deduplicationWindow);
return isNew != null && !isNew;
}
}
3. Aggregazioni idempotenti
Quando si gestiscono operazioni di aggregazione, considera l'uso di tecniche di aggregazione idempotenti. Ad esempio, invece di memorizzare una somma in corso, memorizza i valori individuali e calcola la somma al volo:
public class IdempotentAggregator {
private final Map values = new ConcurrentHashMap<>();
public void addValue(String key, double value) {
values.put(key, value);
}
public double getSum() {
return values.values().stream().mapToDouble(Double::doubleValue).sum();
}
}
Questo approccio garantisce che anche se un messaggio viene elaborato più volte, non influenzerà il risultato finale dell'aggregazione.
Conclusione
Implementare consumatori idempotenti in Kafka potrebbe sembrare un compito arduo, ma con queste migliori pratiche e tecniche, gestirai i duplicati come un professionista in poco tempo. Ricorda, la chiave è sempre aspettarsi l'inaspettato e progettare il tuo sistema con l'idempotenza in mente fin dall'inizio.
Ecco un rapido elenco di controllo da tenere a portata di mano:
- Usa identificatori unici per i messaggi
- Sfrutta la gestione degli offset di Kafka
- Implementa una strategia di deduplicazione robusta
- Progetta operazioni naturalmente idempotenti quando possibile
- Sii consapevole delle trappole comuni e come evitarle
- Considera tecniche avanzate per casi d'uso specifici
Seguendo queste linee guida, non solo migliorerai l'affidabilità e la coerenza dei tuoi sistemi basati su Kafka, ma ti risparmierai anche innumerevoli ore di debug e mal di testa. E diciamocelo, non è forse quello che tutti cerchiamo?
Ora vai e conquista quei messaggi duplicati! Il tuo futuro te stesso (e il tuo team operativo) ti ringrazierà.
"Nel mondo dei consumatori Kafka, l'idempotenza non è solo una caratteristica – è un superpotere." – Un saggio sviluppatore (probabilmente)
Buona programmazione, e che i tuoi consumatori siano sempre idempotenti!