Stiamo per costruire un backend che combina la potenza dei modelli di linguaggio di grandi dimensioni (LLM) con la precisione dei database vettoriali utilizzando LangChain. Il risultato? Un'API che può comprendere il contesto, recuperare informazioni pertinenti e generare risposte simili a quelle umane al volo. Non è solo intelligente; è incredibilmente intelligente.
La Rivoluzione RAG: Perché Dovresti Interessartene?
Prima di rimboccarci le maniche e iniziare a programmare, vediamo perché RAG sta suscitando tanto scalpore nel mondo dell'IA:
- Il Contesto è Re: I sistemi RAG comprendono e sfruttano il contesto meglio delle ricerche basate su parole chiave tradizionali.
- Fresco e Rilevante: A differenza degli LLM statici, RAG può accedere e utilizzare informazioni aggiornate.
- Riduzione delle Allucinazioni: Ancorando le risposte ai dati recuperati, RAG aiuta a ridurre quelle fastidiose allucinazioni dell'IA.
- Scalabilità: Man mano che i tuoi dati crescono, cresce anche la conoscenza della tua IA senza bisogno di un addestramento costante.
La Tech Stack: Le Nostre Armi Scelte
Non andiamo in battaglia a mani vuote. Ecco il nostro arsenale:
- LangChain: Il nostro coltellino svizzero per le operazioni LLM (ops, avevo promesso di non usare quella frase, vero?)
- Database Vettoriale: Useremo Pinecone, ma sentiti libero di sostituirlo con il tuo preferito
- LLM: GPT-3.5 o GPT-4 di OpenAI (o qualsiasi altro LLM tu preferisca)
- FastAPI: Per costruire i nostri endpoint API super veloci
- Python: Perché, beh, è Python
Preparare il Terreno
Prima di tutto, prepariamo il nostro ambiente. Avvia il terminale e installiamo i pacchetti necessari:
pip install langchain pinecone-client openai fastapi uvicorn
Ora, creiamo una struttura di base per l'app FastAPI:
from fastapi import FastAPI
from langchain import OpenAI, VectorDBQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
import os
app = FastAPI()
# Inizializza Pinecone
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
# Inizializza OpenAI
llm = OpenAI(temperature=0.7)
# Inizializza gli embeddings
embeddings = OpenAIEmbeddings()
# Inizializza il negozio vettoriale Pinecone
index_name = "your-pinecone-index-name"
vectorstore = Pinecone.from_existing_index(index_name, embeddings)
# Inizializza la catena QA
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", vectorstore=vectorstore)
@app.get("/")
async def root():
return {"message": "Benvenuto nell'API potenziata da RAG!"}
@app.get("/query")
async def query(q: str):
result = qa.run(q)
return {"result": result}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Analizziamo: Cosa Sta Succedendo Qui?
Analizziamo questo codice come se fosse una rana in una lezione di biologia al liceo (ma molto più eccitante):
- Stiamo configurando FastAPI come nostro framework web.
- La classe
OpenAIdi LangChain è la nostra porta d'accesso all'LLM. VectorDBQAè la bacchetta magica che combina il nostro database vettoriale con l'LLM per il question-answering.- Stiamo usando Pinecone come nostro database vettoriale, ma potresti sostituirlo con alternative come Weaviate o Milvus.
- L'endpoint
/queryè dove avviene la magia RAG. Prende una domanda, la esegue attraverso la nostra catena QA e restituisce il risultato.
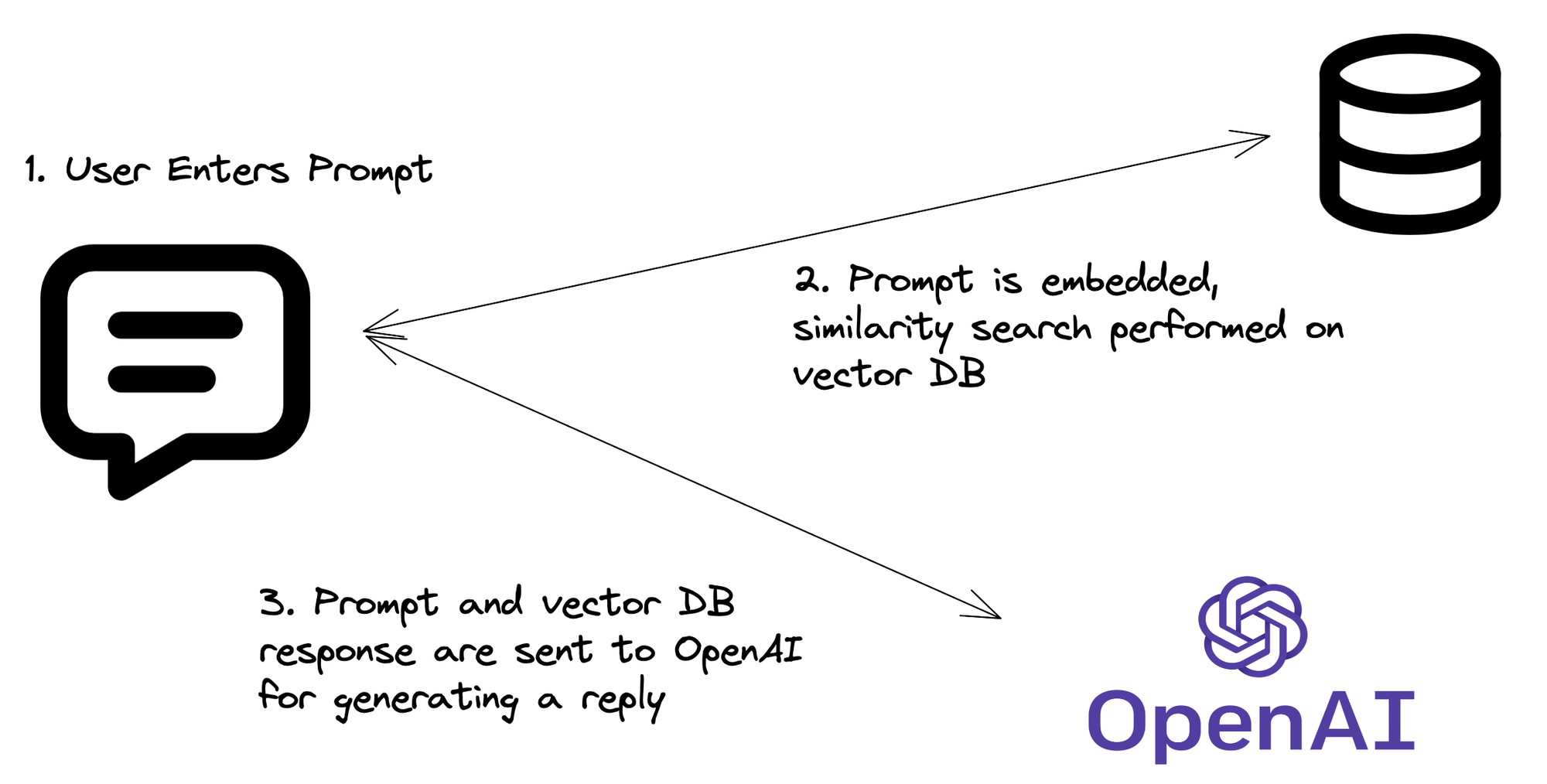
Il Processo RAG: Come Funziona Davvero
Ora che abbiamo il codice, analizziamo il processo RAG:
- Embedding della Query: La tua API riceve una domanda, che viene poi convertita in un embedding vettoriale.
- Ricerca Vettoriale: Questo embedding viene utilizzato per cercare nell'indice Pinecone vettori simili (cioè, informazioni pertinenti).
- Recupero del Contesto: I documenti o i frammenti più pertinenti vengono recuperati da Pinecone.
- Magia LLM: La domanda originale e il contesto recuperato vengono inviati all'LLM.
- Generazione della Risposta: L'LLM genera una risposta basata sulla domanda e sul contesto recuperato.
- Ritorno API: La tua API restituisce questa risposta intelligente e consapevole del contesto.
Potenziare il Tuo RAG: Tecniche Avanzate
Pronto a portare il tuo sistema RAG da "abbastanza cool" a "wow, è incredibile"? Prova queste tecniche avanzate:
1. Ricerca Ibrida
Combina la ricerca vettoriale con la ricerca tradizionale basata su parole chiave per risultati ancora migliori:
from langchain.retrievers import PineconeHybridSearchRetriever
hybrid_retriever = PineconeHybridSearchRetriever(
embeddings=embeddings,
index=vectorstore.pinecone_index
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=hybrid_retriever)
2. Riordinamento
Implementa un passaggio di riordinamento per perfezionare i documenti recuperati:
from langchain.retrievers import RePhraseQueryRetriever
rephraser = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=rephraser)
3. Risposte in Streaming
Per un'esperienza più interattiva, trasmetti in streaming le risposte della tua API:
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
@app.get("/stream")
async def stream_query(q: str):
async def event_generator():
for token in qa.run(q):
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
Possibili Trappole: Fai Attenzione!
Per quanto RAG sia straordinario, non è privo di stranezze. Ecco alcune cose a cui prestare attenzione:
- Limitazioni della Finestra di Contesto: Gli LLM hanno una dimensione massima del contesto. Assicurati che i documenti recuperati non superino questo limite.
- Rilevanza vs. Diversità: Bilanciare risultati pertinenti con informazioni diversificate può essere complicato. Sperimenta con i tuoi parametri di recupero.
- Le Allucinazioni Non Sono Scomparse: Sebbene RAG riduca le allucinazioni, non le elimina. Implementa sempre meccanismi di salvaguardia e verifica dei fatti.
- Costi API: Ricorda, ogni query comporta potenzialmente più chiamate API (embedding, ricerca vettoriale, LLM). Tieni d'occhio le spese!
Conclusione: Perché Questo è Importante
Implementare RAG nel tuo backend non riguarda solo essere all'avanguardia (anche se è un bel bonus). Si tratta di creare applicazioni più intelligenti e consapevoli del contesto che possono comprendere e rispondere alle domande degli utenti in modi che prima erano impossibili.
Combinando la vasta conoscenza degli LLM con le informazioni specifiche e aggiornate nel tuo database vettoriale, stai creando un sistema che è più della somma delle sue parti. È come dare alla tua API un superpotere: la capacità di comprendere, ragionare e generare risposte simili a quelle umane basate su dati in tempo reale.
"Il futuro è già qui – è solo distribuito in modo non uniforme." - William Gibson
Bene, ora sei uno dei fortunati con un pezzo di quel futuro. Vai avanti e costruisci cose straordinarie!
Spunti di Riflessione
Mentre implementi RAG nei tuoi progetti, considera queste domande:
- Come puoi garantire la privacy e la sicurezza dei dati utilizzati nel tuo sistema RAG?
- Quali considerazioni etiche entrano in gioco quando si distribuiscono API potenziate dall'IA?
- Come potrebbero evolversi i sistemi RAG man mano che gli LLM e i database vettoriali continuano a progredire?
Le risposte a queste domande plasmeranno il futuro delle applicazioni potenziate dall'IA. E ora, sei in prima linea in quella rivoluzione. Buona programmazione!