Fissare le goroutine ai thread del sistema operativo può ridurre significativamente le penalità NUMA e la contesa dei lock nei sistemi HFT basati su Go. Esploreremo come sfruttare runtime.LockOSThread(), gestire l'affinità dei thread e ottimizzare il tuo codice Go per architetture multi-socket.
L'incubo NUMA
Prima di addentrarci nei dettagli del fissaggio delle goroutine, facciamo un rapido riepilogo del perché le architetture NUMA (Non-Uniform Memory Access) possono essere un problema per i sistemi HFT:
- La latenza di accesso alla memoria varia a seconda di quale core della CPU accede a quale banco di memoria
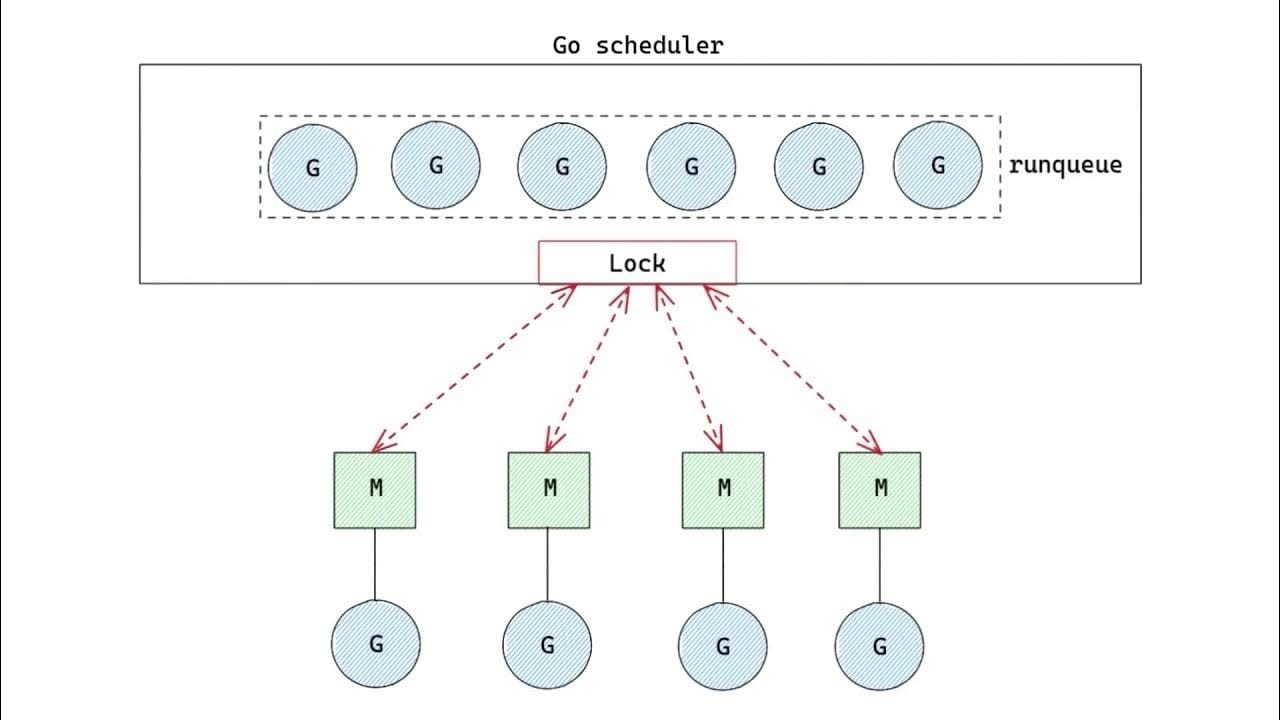
- Lo scheduler di Go, di default, non considera la topologia NUMA quando pianifica le goroutine
- Questo può portare a frequenti accessi alla memoria tra socket, causando un degrado delle prestazioni
Nel mondo dell'HFT, dove ogni nanosecondo conta, queste penalità NUMA possono fare la differenza tra profitto e perdita. Ma non temere, abbiamo gli strumenti per domare questa bestia!
Fissare le Goroutine: Il Segreto
La chiave per mitigare i problemi NUMA in Go è fissare le goroutine a specifici thread del sistema operativo, che possono poi essere legati a particolari core della CPU. Questo assicura che le nostre goroutine rimangano ferme e non vaghino tra i nodi NUMA. Ecco come possiamo ottenere questo:
1. Blocca la goroutine corrente al suo thread del sistema operativo
func init() {
runtime.LockOSThread()
}
Questa chiamata di funzione assicura che la goroutine corrente sia bloccata al thread del sistema operativo su cui sta girando. È cruciale chiamarla all'inizio del tuo programma o in qualsiasi goroutine che deve essere fissata.
2. Imposta l'affinità del thread
Ora che abbiamo bloccato la nostra goroutine a un thread del sistema operativo, dobbiamo dire al sistema operativo su quale core della CPU vogliamo che questo thread giri. Purtroppo, Go non fornisce un modo nativo per farlo, quindi dovremo usare un po' di magia cgo:
// #include <pthread.h>
// #include <stdlib.h>
import "C"
import "unsafe"
func setThreadAffinity(cpuID int) {
runtime.LockOSThread()
var cpuset C.cpu_set_t
C.CPU_ZERO(&cpuset)
C.CPU_SET(C.int(cpuID), &cpuset)
thread := C.pthread_self()
_, err := C.pthread_setaffinity_np(thread, C.size_t(unsafe.Sizeof(cpuset)), &cpuset)
if err != nil {
panic(err)
}
}
Questa funzione utilizza l'API dei thread POSIX per impostare l'affinità del thread corrente a un core specifico della CPU. Dovrai chiamare questa funzione da ogni goroutine che deve essere fissata a un core particolare.
Mettere Tutto Insieme: Una Pipeline di Dati di Mercato ad Alte Prestazioni
Ora che abbiamo i mattoni, vediamo come possiamo applicarli a uno scenario reale di HFT. Creeremo una semplice pipeline di dati di mercato che elabora i tick in arrivo e calcola alcune statistiche di base.
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
type MarketData struct {
Symbol string
Price float64
}
func marketDataProcessor(id int, inputChan <-chan MarketData, wg *sync.WaitGroup) {
defer wg.Done()
// Fissa questa goroutine a un core specifico della CPU
setThreadAffinity(id % runtime.NumCPU())
var count int
var sum float64
start := time.Now()
for data := range inputChan {
count++
sum += data.Price
if count % 1000000 == 0 {
avgPrice := sum / float64(count)
elapsed := time.Since(start)
fmt.Printf("Processor %d: Processati %d tick, Prezzo Medio: %.2f, Tempo: %v\n", id, count, avgPrice, elapsed)
start = time.Now()
count = 0
sum = 0
}
}
}
func main() {
runtime.GOMAXPROCS(runtime.NumCPU())
numProcessors := 4
inputChan := make(chan MarketData, 10000)
var wg sync.WaitGroup
// Avvia i processori di dati di mercato
for i := 0; i < numProcessors; i++ {
wg.Add(1)
go marketDataProcessor(i, inputChan, &wg)
}
// Simula l'arrivo di dati di mercato
go func() {
for i := 0; ; i++ {
inputChan <- MarketData{
Symbol: fmt.Sprintf("STOCK%d", i%100),
Price: float64(i % 10000) / 100,
}
}
}()
wg.Wait()
}
In questo esempio, creiamo più processori di dati di mercato, ciascuno fissato a un core specifico della CPU. Questo approccio ci aiuta a massimizzare l'uso del nostro sistema multi-core riducendo al minimo le penalità NUMA.
I Pro e i Contro del Fissaggio delle Goroutine
Prima di impegnarti completamente nel fissaggio delle goroutine, è importante comprendere i compromessi:
Pro:
- Riduzione delle penalità NUMA nei sistemi multi-socket
- Miglioramento della località della cache e riduzione del thrashing della cache
- Migliore controllo sulla distribuzione del carico tra i core della CPU
- Potenziale per miglioramenti significativi delle prestazioni negli scenari HFT
Contro:
- Aumento della complessità nel codice e nel design del sistema
- Potenziale per una distribuzione del carico non uniforme se non gestita con attenzione
- Perdita di alcuni dei benefici di scheduling integrati di Go
- Può richiedere codice specifico per il sistema operativo per la gestione dell'affinità dei thread
Misurare l'Impatto: Prima e Dopo
Per apprezzare veramente i benefici del fissaggio delle goroutine, è fondamentale misurare le prestazioni del tuo sistema prima e dopo l'implementazione. Ecco alcune metriche chiave su cui concentrarsi:
- Percentili di latenza (p50, p99, p99.9)
- Throughput (messaggi elaborati al secondo)
- Utilizzo della CPU tra i core
- Modelli di accesso alla memoria (utilizzando strumenti come Intel VTune o AMD uProf)
Consiglio: Usa uno strumento come pprof per generare profili di CPU e memoria della tua applicazione prima e dopo aver implementato il fissaggio delle goroutine. Questo può fornire preziose informazioni su come le tue ottimizzazioni stanno influenzando il comportamento del sistema.
Oltre al Fissaggio: Ottimizzazioni Aggiuntive per i Carichi di Lavoro HFT
Sebbene il fissaggio delle goroutine sia una tecnica potente, è solo un pezzo del puzzle quando si tratta di ottimizzare Go per i carichi di lavoro HFT. Ecco alcune strategie aggiuntive da considerare:
1. Ottimizzazione dell'allocazione della memoria
Minimizza le pause della garbage collection riducendo le allocazioni:
- Usa sync.Pool per oggetti allocati frequentemente
- Considera l'uso di array invece di slice per dati a dimensione fissa
- Prealloca i buffer quando possibile
2. Strutture dati senza lock
Riduci la contesa utilizzando operazioni atomiche e strutture dati senza lock:
import "sync/atomic"
type AtomicFloat64 struct{ v uint64 }
func (f *AtomicFloat64) Store(val float64) {
atomic.StoreUint64(&f.v, math.Float64bits(val))
}
func (f *AtomicFloat64) Load() float64 {
return math.Float64frombits(atomic.LoadUint64(&f.v))
}
3. Istruzioni SIMD
Sfrutta le istruzioni SIMD (Single Instruction, Multiple Data) per l'elaborazione parallela dei dati di mercato. Sebbene Go non abbia supporto diretto per SIMD, puoi usare assembly o cgo per accedere a queste potenti istruzioni.
Conclusione: Il Futuro di Go nell'HFT
Come abbiamo visto, con un po' di impegno e alcune tecniche avanzate come il fissaggio delle goroutine, Go può essere uno strumento formidabile nell'arena HFT. Ma il viaggio non finisce qui. Il team di Go sta costantemente lavorando su miglioramenti al runtime e allo scheduler, che potrebbero rendere alcune di queste ottimizzazioni manuali non necessarie in futuro.
Ricorda, l'ottimizzazione prematura è la radice di tutti i mali. Profilare sempre la tua applicazione prima per identificare i veri colli di bottiglia prima di immergerti in tecniche avanzate come il fissaggio delle goroutine. E quando ottimizzi, misura, misura, misura!
Buon trading, e che le tue goroutine trovino sempre la strada giusta verso il core della CPU giusto!
"Nel mondo dell'HFT, ogni nanosecondo conta. Ma nel mondo dell'ingegneria del software, la leggibilità e la manutenibilità contano ancora di più. Trova un equilibrio, e sarai d'oro." - Saggio Vecchio Gopher
Ulteriori Letture
- Documentazione del Pacchetto Runtime di Go
- Scheduling in Go di William Kennedy
- Problema GitHub di Go: Supporto per l'affinità della CPU
- Scheduler del Runtime di Go di Kavya Joshi
Ora vai avanti e conquista quei nodi NUMA! E ricorda, con grande potere viene grande responsabilità. Usa saggiamente le tue nuove abilità di fissaggio delle goroutine!