La degradazione graduale riguarda il mantenimento della funzionalità del tuo sistema, anche se non è al 100%. Esploreremo strategie come interruttori automatici, limitazione della velocità e prioritizzazione per aiutare il tuo backend a resistere a qualsiasi tempesta. Allacciate le cinture; sarà un viaggio accidentato (ma educativo)!
Perché Preoccuparsi della Degradazione Graduale?
Ammettiamolo: in un mondo ideale, i nostri sistemi funzionerebbero perfettamente 24/7. Ma viviamo nel mondo reale, dove la Legge di Murphy è sempre in agguato dietro l'angolo. La degradazione graduale è il nostro modo di sfidare Murphy e dire: "Bel tentativo, ma ce l'abbiamo fatta."
Ecco perché è importante:
- Mantiene vive le funzionalità critiche quando le cose vanno storte
- Previene i guasti a cascata che possono abbattere l'intero sistema
- Migliora l'esperienza utente durante i periodi di stress elevato
- Ti dà il tempo di risolvere i problemi senza una crisi totale
Strategie per la Degradazione Graduale
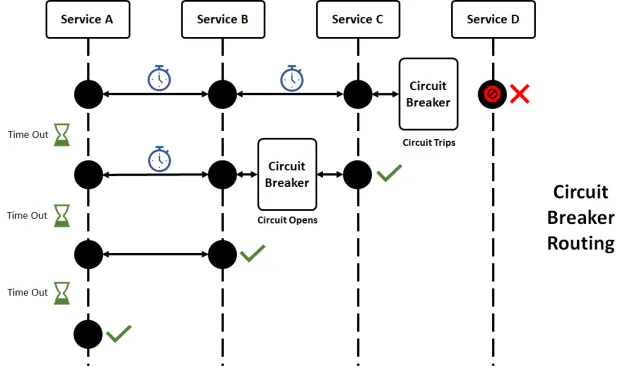
1. Interruttori Automatici: Il Quadro Elettrico del Tuo Sistema
Ricordi quando da bambino facevi saltare un fusibile collegando troppe luci di Natale? Gli interruttori automatici nel software funzionano in modo simile, proteggendo il tuo sistema dal sovraccarico.
Ecco una semplice implementazione usando la libreria Hystrix:
public class ExampleCommand extends HystrixCommand {
private final String name;
public ExampleCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// Questo potrebbe essere una chiamata API o una query al database
return "Ciao " + name + "!";
}
@Override
protected String getFallback() {
return "Ciao Ospite!";
}
}
In questo esempio, se il metodo run() fallisce o impiega troppo tempo, l'interruttore automatico interviene e chiama getFallback(). È come avere un generatore di riserva per il tuo codice!
2. Limitazione della Velocità: Insegnare Buone Maniere alla Tua API
La limitazione della velocità è come essere un buttafuori in un club. Non vuoi che troppe richieste arrivino tutte insieme, altrimenti le cose potrebbero diventare disordinate. Ecco come potresti implementarla usando Spring Boot e Bucket4j:
@RestController
public class ApiController {
private final Bucket bucket;
public ApiController() {
Bandwidth limit = Bandwidth.classic(20, Refill.greedy(20, Duration.ofMinutes(1)));
this.bucket = Bucket.builder()
.addLimit(limit)
.build();
}
@GetMapping("/api/resource")
public ResponseEntity getResource() {
if (bucket.tryConsume(1)) {
return ResponseEntity.ok("Ecco la tua risorsa!");
}
return ResponseEntity.status(429).body("Troppe richieste, riprova più tardi.");
}
}
Questa configurazione consente 20 richieste al minuto. Di più, e ti viene gentilmente chiesto di tornare più tardi. È come se la tua API avesse imparato a fare la fila!
3. Prioritizzazione: Non Tutte le Richieste Sono Create Uguali
Quando le cose si fanno difficili, devi sapere cosa prioritizzare. È come il triage in un pronto soccorso – operazioni critiche prima, GIF di gatti dopo (scusate, amanti dei gatti).
Considera l'implementazione di una coda di priorità per le tue richieste:
public class PriorityRequestQueue {
private PriorityQueue queue;
public PriorityRequestQueue() {
this.queue = new PriorityQueue<>((r1, r2) -> r2.getPriority() - r1.getPriority());
}
public void addRequest(Request request) {
queue.offer(request);
}
public Request processNextRequest() {
return queue.poll();
}
}
Questo assicura che le richieste ad alta priorità (come pagamenti o azioni critiche degli utenti) vengano elaborate per prime quando le risorse sono limitate.
L'Arte di Fallire con Grazia
Ora che abbiamo coperto alcune strategie, parliamo dell'arte di fallire con grazia. Non si tratta solo di evitare un crollo totale; si tratta di mantenere la dignità di fronte alle avversità. Ecco alcuni consigli:
- Comunicazione Chiara: Quando si degradano i servizi, sii trasparente con i tuoi utenti. Un semplice "Stiamo riscontrando una domanda elevata, alcune funzionalità potrebbero essere temporaneamente non disponibili" fa molta strada.
- Degradazione Graduale: Non passare da 100 a 0. Disabilita prima le funzionalità non critiche, mantenendo intatta la funzionalità principale il più a lungo possibile.
- Ritenti Intelligenti: Implementa un backoff esponenziale per i ritenti per evitare di sovraccaricare servizi già stressati.
- Strategie di Caching: Usa il caching in modo saggio per ridurre il carico sui servizi backend durante i picchi di traffico.
Monitoraggio: Il Tuo Sistema di Allerta Precoce
Implementare strategie di degradazione graduale è fantastico, ma come fai a sapere quando attivarle? Entra in gioco il monitoraggio – il sistema di allerta precoce del tuo sistema.
Considera l'uso di strumenti come Prometheus e Grafana per tenere d'occhio le metriche chiave:
- Tempi di risposta
- Tassi di errore
- Utilizzo di CPU e memoria
- Lunghezze delle code
Imposta avvisi che si attivano non solo quando le cose vanno male, ma quando iniziano a sembrare un po' incerte. È come avere una previsione del tempo per il tuo sistema – vuoi sapere della tempesta prima che colpisca.
Testare le Tue Strategie di Degradazione
Non distribuiresti codice senza testarlo, giusto? (Giusto?!) Lo stesso vale per le tue strategie di degradazione. Entra in gioco l'ingegneria del caos – l'arte di rompere le cose di proposito.
Strumenti come Chaos Monkey possono aiutarti a simulare guasti e scenari di carico elevato in un ambiente controllato. È come un'esercitazione antincendio per il tuo sistema. Certo, potrebbe essere un po' snervante, ma è meglio scoprire che gli irrigatori non funzionano durante un'esercitazione piuttosto che durante un vero incendio.
Esempio Reale: L'Approccio di Netflix
Diamo un'occhiata rapida a come il gigante dello streaming Netflix gestisce la degradazione graduale. Usano una tecnica chiamata "fallback per priorità". Ecco una versione semplificata del loro approccio:
- Prova a recuperare raccomandazioni personalizzate per un utente.
- Se fallisce, ripiega sui titoli popolari per la loro regione.
- Se i dati regionali non sono disponibili, mostra i titoli popolari generali.
- Come ultima risorsa, visualizza un elenco statico e predefinito di titoli.
Questo assicura che gli utenti vedano sempre qualcosa, anche se non è l'esperienza personalizzata ideale. È un ottimo esempio di degradazione della funzionalità pur fornendo valore.
Conclusione: Abbraccia il Caos
Progettare per la degradazione graduale non riguarda solo la gestione dei guasti; si tratta di abbracciare la natura caotica dei sistemi distribuiti. È accettare che le cose andranno male e pianificare di conseguenza. È la differenza tra dire "Ops, colpa nostra!" e "Abbiamo tutto sotto controllo."
Ricorda:
- Implementa interruttori automatici per prevenire guasti a cascata
- Usa la limitazione della velocità per gestire scenari di carico elevato
- Prioritizza le operazioni critiche quando le risorse sono scarse
- Comunica chiaramente con gli utenti durante gli stati degradati
- Monitora, testa e migliora continuamente le tue strategie di degradazione
Seguendo queste strategie, non stai solo costruendo un sistema; stai costruendo un guerriero resiliente e collaudato pronto ad affrontare qualsiasi caos il mondo digitale gli lanci contro. Ora vai avanti e degrada con grazia!
"Il vero test di un sistema non è come si comporta quando tutto va bene, ma come si comporta quando tutto va male." - Filosofo DevOps Anonimo
Hai storie di guerra sulla degradazione graduale nei tuoi sistemi? Condividile nei commenti! Dopotutto, l'incubo di un sviluppatore è l'opportunità di apprendimento di un altro. Buona programmazione, e che i tuoi sistemi degradino sempre con grazia e stile!