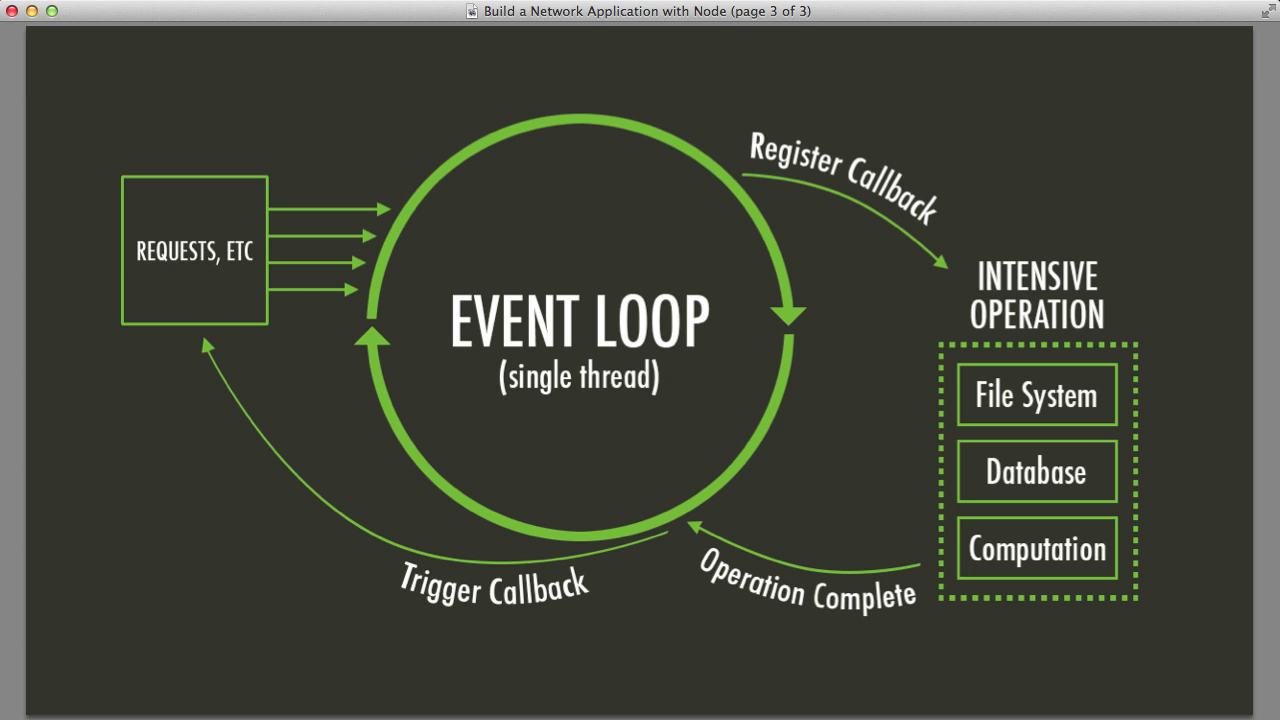
Il ciclo degli eventi è il cuore di Node.js, pompando operazioni asincrone attraverso la tua applicazione come il sangue nelle vene. È a singolo thread, il che significa che può gestire un'operazione alla volta. Ma non lasciarti ingannare: è incredibilmente veloce ed efficiente.
Ecco una visione semplificata di come funziona:
- Esegui codice sincrono
- Elabora i timer (setTimeout, setInterval)
- Elabora i callback di I/O
- Elabora i callback di setImmediate()
- Chiudi i callback
- Ripeti il ciclo
Sembra semplice, vero? Beh, le cose possono complicarsi quando inizi ad accumulare operazioni complesse. È qui che entrano in gioco i nostri modelli avanzati.
Modello 1: Worker Threads - Follia del Multithreading
Ricordi quando ho detto che Node.js è a singolo thread? Beh, non è tutta la verità. Ecco i Worker Threads – la risposta di Node.js ai compiti intensivi per la CPU che altrimenti bloccherebbero il nostro prezioso ciclo degli eventi.
Ecco un rapido esempio di come utilizzare i worker threads:
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename);
worker.on('message', (message) => {
console.log('Ricevuto:', message);
});
worker.postMessage('Ciao, Worker!');
} else {
parentPort.on('message', (message) => {
console.log('Worker ha ricevuto:', message);
parentPort.postMessage('Ciao, Main thread!');
});
}
Questo codice crea un worker thread che può funzionare in parallelo con il thread principale, permettendoti di delegare calcoli pesanti senza bloccare il ciclo degli eventi. È come avere un assistente personale per i tuoi compiti intensivi per la CPU!
Quando usare i Worker Threads
- Operazioni legate alla CPU (calcoli complessi, elaborazione dati)
- Esecuzione parallela di compiti indipendenti
- Miglioramento delle prestazioni delle operazioni sincrone
Consiglio da esperto: Non esagerare con i worker threads! Hanno un overhead, quindi usali saggiamente per compiti che traggono veramente beneficio dalla parallelizzazione.
Modello 2: Clustering - Perché Due Teste Sono Meglio di Una
Cosa c'è di meglio di un processo Node.js? Più processi Node.js! Questa è l'idea dietro il clustering. Ti permette di creare processi figli che condividono le porte del server, distribuendo efficacemente il carico di lavoro su più core della CPU.
Ecco un semplice esempio di clustering:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} è in esecuzione`);
// Crea i worker.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} è morto`);
});
} else {
// I worker possono condividere qualsiasi connessione TCP
// In questo caso, è un server HTTP
http.createServer((req, res) => {
res.writeHead(200);
res.end('Ciao Mondo\n');
}).listen(8000);
console.log(`Worker ${process.pid} avviato`);
}
Questo codice crea più processi worker, ognuno in grado di gestire richieste HTTP. È come clonare il tuo server e avere un esercito di mini-server pronti a gestire le richieste in arrivo!
Vantaggi del Clustering
- Miglioramento delle prestazioni e del throughput
- Migliore utilizzo dei sistemi multi-core
- Aumento dell'affidabilità (se un worker si blocca, gli altri possono subentrare)
Ricorda: Con grande potere viene grande responsabilità. Il clustering può aumentare significativamente la complessità della tua app, quindi usalo quando hai veramente bisogno di scalare orizzontalmente.
Modello 3: Async Iterators - Domare la Bestia del Flusso di Dati
Gestire grandi set di dati o flussi in Node.js può essere come cercare di bere da un idrante. Gli async iterators vengono in soccorso, permettendoti di elaborare i dati pezzo per pezzo senza sovraccaricare il tuo ciclo degli eventi.
Vediamo un esempio:
const { createReadStream } = require('fs');
const { createInterface } = require('readline');
async function* processFileLines(filename) {
const rl = createInterface({
input: createReadStream(filename),
crlfDelay: Infinity
});
for await (const line of rl) {
yield line;
}
}
(async () => {
for await (const line of processFileLines('huge_file.txt')) {
console.log('Elaborato:', line);
// Fai qualcosa con ogni riga
}
})();
Questo codice legge un file potenzialmente enorme riga per riga, permettendoti di elaborare ogni riga senza caricare l'intero file in memoria. È come avere un nastro trasportatore per i tuoi dati, che te li fornisce a un ritmo gestibile!
Perché gli Async Iterators Sono Fantastici
- Uso efficiente della memoria per grandi set di dati
- Modo naturale di gestire flussi di dati asincroni
- Miglior leggibilità per pipeline di elaborazione dati complesse
Mettere Tutto Insieme: Uno Scenario Reale
Immaginiamo di costruire un sistema di analisi dei log che deve elaborare file di log enormi, eseguire calcoli intensivi per la CPU e fornire risultati tramite un'API. Ecco come potremmo combinare questi modelli:
const cluster = require('cluster');
const { Worker } = require('worker_threads');
const express = require('express');
const { processFileLines } = require('./fileProcessor');
if (cluster.isMaster) {
console.log(`Master ${process.pid} è in esecuzione`);
// Crea i worker per il server API
for (let i = 0; i < 2; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} è morto`);
});
} else {
const app = express();
app.get('/analyze', async (req, res) => {
const results = [];
const worker = new Worker('./analyzeWorker.js');
for await (const line of processFileLines('huge_log_file.txt')) {
worker.postMessage(line);
}
worker.on('message', (result) => {
results.push(result);
});
worker.on('exit', () => {
res.json(results);
});
});
app.listen(3000, () => console.log(`Worker ${process.pid} avviato`));
}
In questo esempio, stiamo usando:
- Clustering per creare più processi server API
- Worker threads per delegare l'analisi dei log intensiva per la CPU
- Async iterators per elaborare efficientemente grandi file di log
Questa combinazione ci permette di gestire più richieste concorrenti, elaborare grandi file in modo efficiente e eseguire calcoli complessi senza bloccare il ciclo degli eventi. È come avere una macchina ben oliata dove ogni parte conosce il suo lavoro e lavora in armonia con le altre!
Conclusione: Lezioni Apprese
Come abbiamo visto, gestire la concorrenza in Node.js riguarda la comprensione del ciclo degli eventi e sapere quando utilizzare modelli avanzati. Ecco i punti chiave:
- Usa i worker threads per compiti intensivi per la CPU che bloccherebbero il ciclo degli eventi
- Implementa il clustering per sfruttare i sistemi multi-core e migliorare la scalabilità
- Sfrutta gli async iterators per l'elaborazione efficiente di grandi set di dati o flussi
- Combina questi modelli strategicamente in base al tuo caso d'uso specifico
Ricorda, con grande potere viene grande... complessità. Questi modelli sono strumenti potenti, ma introducono anche nuove sfide in termini di debug, gestione dello stato e architettura complessiva dell'applicazione. Usali con giudizio e profila sempre la tua applicazione per assicurarti di ottenere effettivamente benefici da queste tecniche avanzate.
Spunti di Riflessione
Mentre ti addentri nel mondo della concorrenza in Node.js, ecco alcune domande su cui riflettere:
- Come potrebbero questi modelli influenzare la gestione degli errori e la resilienza della tua applicazione?
- Quali sono i compromessi tra l'uso di worker threads e la creazione di processi separati?
- Come puoi monitorare e fare debug efficacemente delle applicazioni che utilizzano questi modelli di concorrenza avanzati?
Il viaggio per padroneggiare la concorrenza in Node.js è in corso, ma armato di questi modelli, sei ben avviato a costruire applicazioni incredibilmente veloci, efficienti e scalabili. Ora vai avanti e conquista quel ciclo degli eventi!
Ricorda: Il miglior codice non è sempre il più complesso. A volte, un'applicazione ben strutturata a singolo thread può superare una mal implementata a multi-thread. Misura sempre, profila e ottimizza in base ai dati di prestazioni del mondo reale.
Buona programmazione, e che i tuoi cicli degli eventi siano sempre ininterrotti (a meno che tu non voglia che lo siano)!