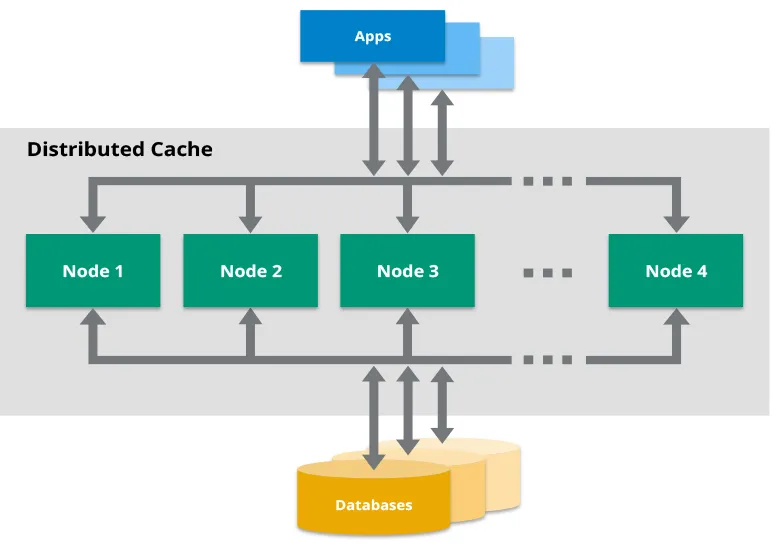
Perché Hazelcast? E Perché Dovresti Interessartene?
Prima di addentrarci nei dettagli, affrontiamo la questione principale: Perché Hazelcast? Nell'ampio panorama delle soluzioni di caching, Hazelcast si distingue come una griglia di dati in-memory distribuita che si integra perfettamente con Java. È simile a Redis, ma con un approccio orientato a Java e alcune funzionalità interessanti che rendono il caching distribuito nei microservizi un gioco da ragazzi.
Ecco un rapido elenco dei motivi per cui Hazelcast potrebbe diventare il tuo nuovo migliore amico:
- API Java nativa (niente più lotte con la serializzazione)
- Calcoli distribuiti (pensa a MapReduce, ma più semplice)
- Protezione integrata contro il "split-brain" (perché le partizioni di rete accadono)
- Scalabilità facile (basta aggiungere più nodi)
Configurare Hazelcast nei Tuoi Microservizi
Iniziamo con le basi. Aggiungere Hazelcast al tuo microservizio Java è sorprendentemente semplice. Prima di tutto, aggiungi la dipendenza al tuo pom.xml:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.1.1</version>
</dependency>
Ora, creiamo una semplice istanza di Hazelcast:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class CacheConfig {
public HazelcastInstance hazelcastInstance() {
return Hazelcast.newHazelcastInstance();
}
}
Voilà! Ora hai un nodo Hazelcast in esecuzione nel tuo microservizio. Ma aspetta, c'è di più!
Pattern di Caching Avanzati
Ora che abbiamo coperto le basi, esploriamo alcuni pattern di caching avanzati che faranno cantare i tuoi microservizi.
1. Caching Read-Through/Write-Through
Questo pattern è come avere un assistente personale per i tuoi dati. Invece di gestire manualmente cosa entra ed esce dalla cache, Hazelcast può farlo per te.
public class UserCacheStore implements MapStore<String, User> {
@Override
public User load(String key) {
// Carica dal database
}
@Override
public void store(String key, User value) {
// Memorizza nel database
}
// Altri metodi...
}
MapConfig mapConfig = new MapConfig("users");
mapConfig.setMapStoreConfig(new MapStoreConfig().setImplementation(new UserCacheStore()));
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Con questa configurazione, Hazelcast caricherà automaticamente i dati dal tuo database quando non sono nella cache e scriverà i dati nel database quando vengono aggiornati nella cache. È come magia, ma meglio perché è solo buona ingegneria.
2. Pattern di Near Cache
A volte, hai bisogno che i dati siano velocissimi, anche in un ambiente distribuito. Entra in gioco il pattern di Near Cache. È come avere una cache per la tua cache. Meta, vero?
NearCacheConfig nearCacheConfig = new NearCacheConfig();
nearCacheConfig.setName("users");
nearCacheConfig.setTimeToLiveSeconds(300);
MapConfig mapConfig = new MapConfig("users");
mapConfig.setNearCacheConfig(nearCacheConfig);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Questa configurazione crea una cache locale su ciascun nodo Hazelcast, riducendo le chiamate di rete e accelerando le operazioni di lettura. È particolarmente utile per i dati che vengono letti frequentemente ma aggiornati raramente.
3. Politiche di Eviction
La memoria è preziosa, specialmente nei microservizi. Hazelcast offre politiche di eviction sofisticate per garantire che la tua cache non diventi un divoratore di memoria.
MapConfig mapConfig = new MapConfig("users");
mapConfig.setEvictionConfig(
new EvictionConfig()
.setEvictionPolicy(EvictionPolicy.LRU)
.setMaxSizePolicy(MaxSizePolicy.PER_NODE)
.setSize(10000)
);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Questa configurazione imposta una politica di eviction LRU (Least Recently Used), garantendo che la tua cache rimanga entro un limite di 10.000 voci per nodo. È come avere un buttafuori per la tua festa di dati, che espelle le voci meno popolari quando le cose si affollano troppo.
Calcoli Distribuiti: Portarli al Livello Successivo
Il caching è fantastico, ma Hazelcast può fare di più. Vediamo come possiamo sfruttare i calcoli distribuiti per potenziare i nostri microservizi.
1. Servizio di Executor Distribuito
Hai bisogno di eseguire un compito su tutto il tuo cluster? Il Servizio di Executor Distribuito di Hazelcast ti copre.
public class UserAnalytics implements Callable<Map<String, Integer>>, HazelcastInstanceAware {
private transient HazelcastInstance hazelcastInstance;
@Override
public Map<String, Integer> call() {
IMap<String, User> users = hazelcastInstance.getMap("users");
// Esegui analisi sui dati locali
return results;
}
@Override
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
}
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IExecutorService executorService = hz.getExecutorService("analytics-executor");
Set<Member> members = hz.getCluster().getMembers();
Map<Member, Future<Map<String, Integer>>> results = executorService.submitToMembers(new UserAnalytics(), members);
// Aggrega i risultati
Map<String, Integer> finalResults = new HashMap<>();
for (Future<Map<String, Integer>> future : results.values()) {
Map<String, Integer> result = future.get();
// Unisci il risultato in finalResults
}
Questo pattern ti permette di eseguire calcoli sui dati dove si trovano, riducendo il movimento dei dati e migliorando le prestazioni. È come portare la funzione ai dati, invece del contrario.
2. Entry Processors
Hai bisogno di aggiornare più voci nella tua cache in modo atomico? Gli Entry Processors sono i tuoi amici.
public class UserUpgradeEntryProcessor implements EntryProcessor<String, User, Object> {
@Override
public Object process(Map.Entry<String, User> entry) {
User user = entry.getValue();
if (user.getPoints() > 1000) {
user.setStatus("GOLD");
entry.setValue(user);
}
return null;
}
}
IMap<String, User> users = hz.getMap("users");
users.executeOnEntries(new UserUpgradeEntryProcessor());
Questo pattern ti permette di eseguire operazioni su più voci senza la necessità di blocchi espliciti o gestione delle transazioni. È come avere una mini-transazione per ogni voce nella tua cache.
Trappole da Evitare
Come con qualsiasi strumento potente, Hazelcast ha il suo set di potenziali trappole. Eccone alcune da tenere a mente:
- Over-caching: Non tutto deve essere memorizzato nella cache. Sii selettivo su cosa metti in Hazelcast.
- Ignorare la serializzazione: Hazelcast ha bisogno di serializzare gli oggetti. Assicurati che i tuoi oggetti siano serializzabili e considera serializer personalizzati per oggetti complessi.
- Trascurare il monitoraggio: Imposta un monitoraggio adeguato per il tuo cluster Hazelcast. Strumenti come Hazelcast Management Center possono essere inestimabili.
- Dimenticare la consistenza: In un sistema distribuito, la consistenza eventuale è spesso la norma. Progetta la tua applicazione di conseguenza.
Conclusione
Abbiamo coperto molti argomenti, dalla configurazione di base ai pattern di caching avanzati e ai calcoli distribuiti. Hazelcast è uno strumento potente che può migliorare significativamente le prestazioni e la scalabilità dei tuoi microservizi Java. Ma ricorda, con grande potere viene grande responsabilità. Usa questi pattern con saggezza e considera sempre le esigenze specifiche della tua applicazione.
Ora, vai avanti e memorizza nella cache come un professionista! I tuoi microservizi (e i tuoi utenti) te ne saranno grati.
"Il modo più veloce per accedere ai dati è non doverci accedere affatto." - Guru della Cache Sconosciuto (probabilmente)
Ulteriori Letture
Se hai fame di ulteriori informazioni, dai un'occhiata a queste risorse:
- Repository GitHub di Hazelcast
- Whitepaper sulle Strategie di Caching di Hazelcast
- Documentazione di Hazelcast
Buon caching!